Voice imitation consists of reproducing one person's voice (Target Voice) from anoter person’s voice (Source Voice), or a synthetic voice from text (Text To Speech) .
HOW IT WORKS ?
Voice Imitation requires learning the mathematical voice model of the Source and Target Voices from their respective recordings (deliberate or from archives audio files).
Then these voice models are processed in order to generate a Voice Imitation Model from the Source Voice to the Target Voice. Thus, a Source Voice can speak with the voice of the Target Voice in real time.
To obtain a better result, the recordings of the voices to be reproduced (the voices of interpreters) by the Voice Imitation, are made in the studio. Then, these recordings are pre-processed to generate the Voice Model in a semi-automatic way.
At this stage, we can already hear a result that is fairly representative of the reproduction of the interpreter’s voice.
Then, a supervised processing of the Voice Model will make it possible to obtain the optimal quality of the reproduction of the voice.
When the voice to reproduce comes from an archive video or audio database, CandyVoice can create its good quality Voice Model only if these archive audio recordings are good quality: are homogeneous (recorded at the same period and in the same acoustic environment), and were made in a environment without noise.
Learn more on the recording procedure
Try the demo
APPLICATIONS:
Text-To-Speech Voices Customization
The TTS available on the market are very expensive. Their creation process is long and complex, and they offer very few voices for each language. Thanks to CandyVoice's Voice Imitation technology, all market’s TTS generic voices can be customized very quickly and easily.
Voice Tech
Customization of Brand Voices for voice interaction-based devices, to enrich the user experience by offering a choice of a multitude voices, according to their preferences and needs.
Health
Voice Backup, and customization of generic voices from speech aid devices (AAC, or Augmented and Alternative Communication) to the voices of patients affected by voice or speech disorders.
Personal avatars
Customization of personal avatar’s voices with detection of mouth movements according to spoken words (Lip Synch).
Messaging and social networks
TTS Voices customization allows you to listen to, rather than read, written messages (emails, text messages, social media posts, etc.) with the voice of their authors.
Video games
The option of real-time voice imitation of the game character by the player improves and enriches the player's experience, increases its immersion in the game, and also protects players data : the voice is biometric data that reveals a multitude of sensitive personal informations.
Please do not hesitate to request the technical documentation.
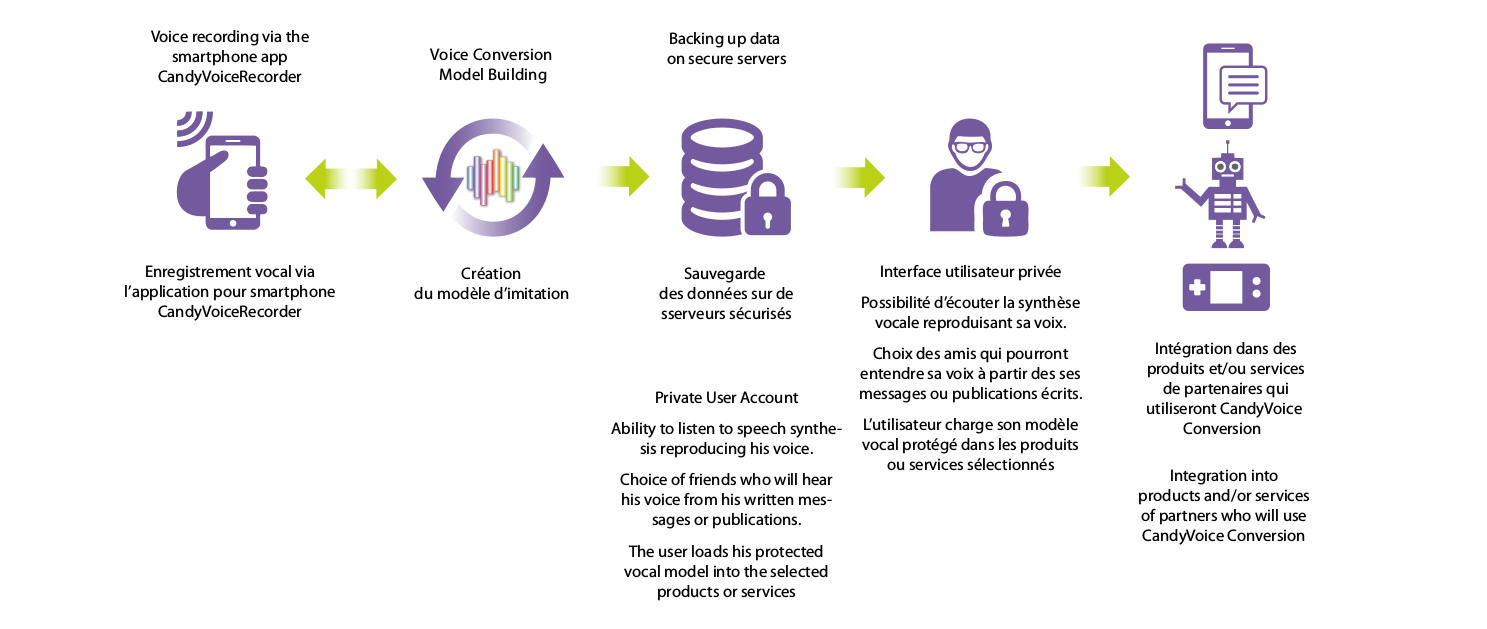
Voice and imitation models creation for individuals
Click/touch to zoom, double click/touch or Escape to come back
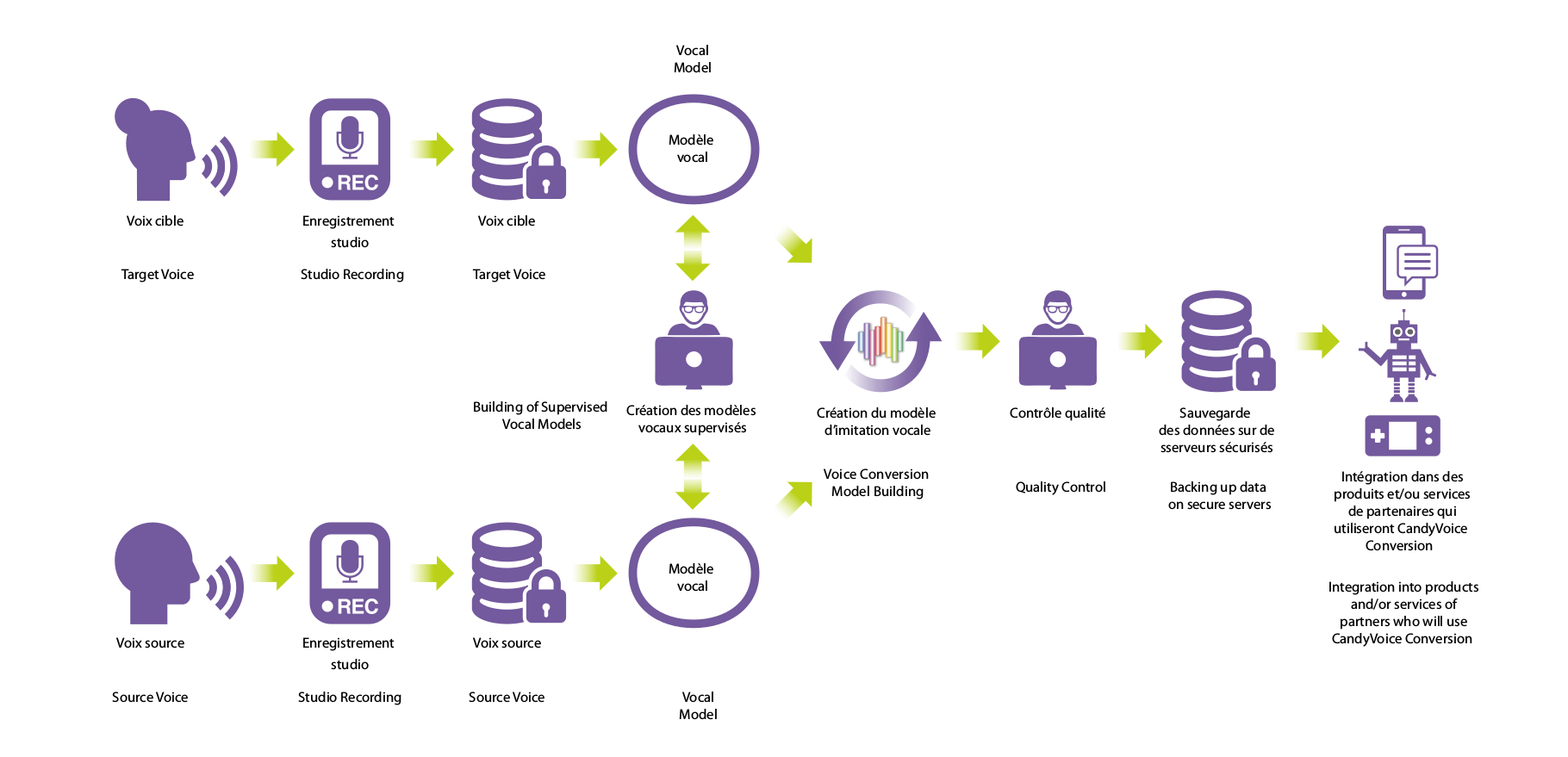
Voice and imitation models creation for companies
Click/touch to zoom, double click/touch or Escape to come back

