L’imitation vocale consiste à reproduire la voix d’une personne (voix cible) à partir de la voix d’une autre personne (voix source), ou d’une voix de synthèse à partir du texte (Text-To-Speech).
Comment ça marche ?
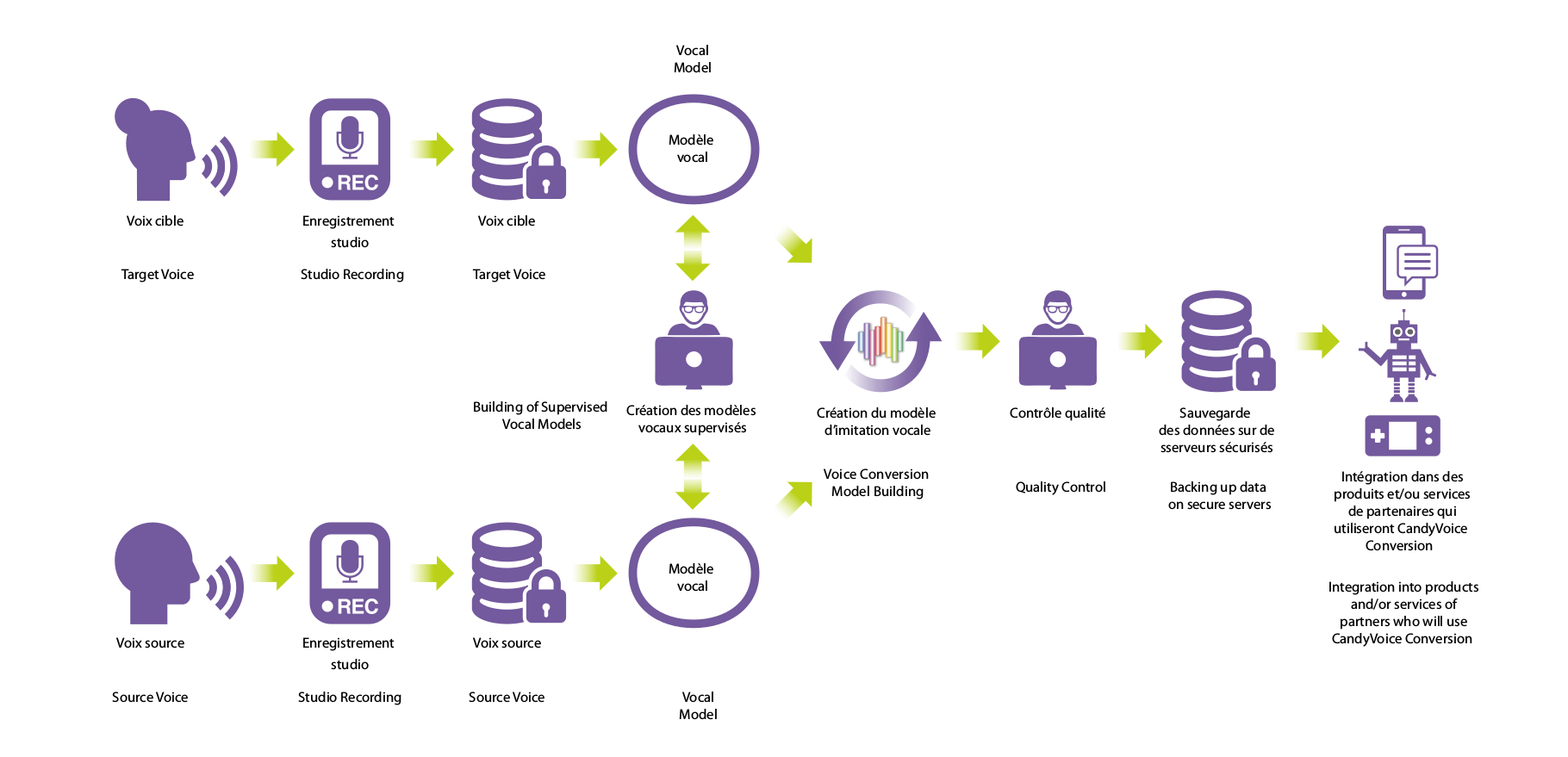
La réalisation de l’imitation vocale nécessite l’apprentissage du modèle vocal mathématique des voix Source et Cible à partir de leurs enregistrements respectifs (délibéré ou à partir de fichiers audio d’archives).
Ces modèles vocaux sont ensuite traités, afin de générer un modèle d’imitation vocale de la Voix Source vers la Voix Cible. Ainsi, on peut faire parler une Voix Source avec la voix de la Voix Cible en temps réel.
Pour un meilleur résultat, les enregistrements des voix à reproduire (les voix des interprètes) par l’imitation vocale, sont réalisés en studio. Ensuite, ces enregistrements sont pré-traités pour créer le modèle vocal de manière semi-automatique.
A ce stade, on peut déjà entendre un résultat assez représentatif de la reproduction de la voix de l’interprète.
Ensuite, un traitement supervisé du modèle vocal permettra d’obtenir la qualité optimale de la reproduction de la voix.
Dans le cas, où la voix à reproduire provient d’une base de données vidéo ou audio d’archives, CandyVoice peut en créer le modèle vocal de qualité, à condition que les enregistrements soient de qualité : homogènes (enregistrés à une même période et dans un même environnement sonore), et dans un environnement sonore sans le bruit.
Voir la procédure d’enregistrement
Essayer la démo
APPLICATIONS :
Personnalisation des voix de Text-To-Speech
Les TTS disponibles sur le marché sont très coûteux, leur processus de création est long et complexe, et ils n’offrent que très peu de voix pour chaque langue. Grâce à la technologie d’imitation vocale de CandyVoice, les voix génériques de tous TTS du marché peuvent être personnalisées très rapidement et facilement.
Voice Tech
Personnalisation des Brand Voices de dispositifs basés sur l’interaction vocale, pour enrichir l’expérience de l’utilisateur en lui offrant le choix parmi une multitude de voix, selon ses préférences et besoins.
Santé
Sauvegarde de la voix, et personnalisation des voix génériques des dispositifs d’aide à la parole (CAA, ou Communication Augmentée et Alternative) à la voix des patients touchés par les troubles de la voix ou de la parole.
Avatars personnels
Personnalisation des voix des avatars avec la détection des mouvements de la bouche en fonction de paroles prononcées (Lip Synch).
Messageries et les réseaux sociaux
La personnalisation des voix de TTS permet d’écouter, plutôt que de lire, des messages écrits (mails, sms, publications sur les réseaux sociaux, etc.) avec la voix de l’auteur.
Jeux vidéo
L’option de l’imitation de la voix du personnage du jeu par le joueur en temps réel permet d’améliorer et d’enrichir l’expérience du joueur, d’en augmenter l’immersion, et aussi de protéger les données concernant les joueurs, la voix étant une donnée biométrique qui révèle une multitude d’informations personnelles sensibles.
N’hésitez pas de nous contacter pour demander la documentation technique.
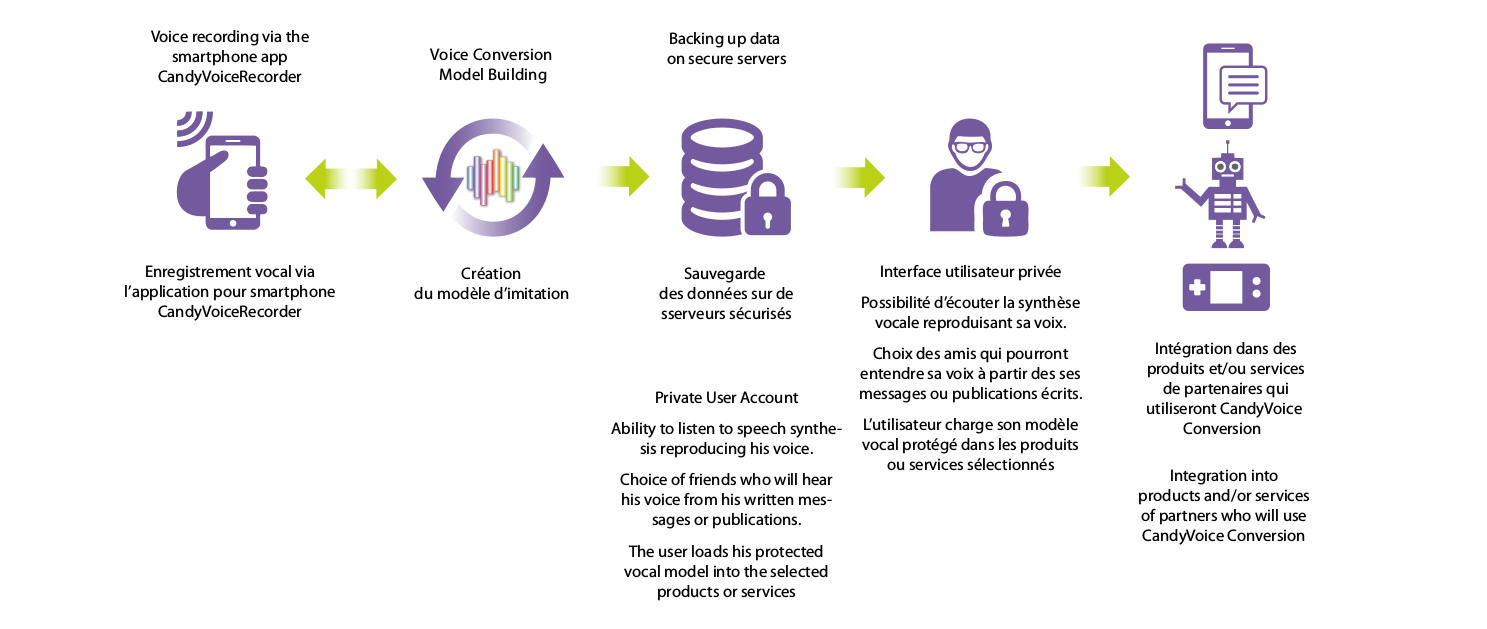
Création des modèles vocaux et d'imitation pour le grand public
Cliquer pour zoomer, double-cliquer ou Echap pour revenir
Création des modèles vocaux et d'imitation pour les professionnels
Cliquer pour zoomer, double-cliquer ou Echap pour revenir

